STRING
Il tipo di dato STRING si compone di due parti:
Un'intestazione che contiene il numero di byte minimo e quello corrente
Una serie (una stringa) di al massimo 32767 byte a seconda della dimensione della memoria del PLC che può contenere qualsiasi tipo di codifica dei caratteri e persino dati binari
Per dettagli, fare riferimento a “Struttura di memoria interna di stringhe di caratteri nel PLC”.
Esempi di operazioni che usano variabili del tipo di dati STRING:
Riempire variabili di stringhe con valori letterali stringa o con funzioni di conversione come WORD_TO_STRING, FP_FORMAT_STRING...
Usare e manipolare variabili di stringa con istruzioni stringhe come CONCAT, LEFT...
Accedere in modo arbitrario a variabili di stringa tramite funzioni di indirizzo speciali come Adr_OfVarOffs… o tramite DUT con elementi sovrapposti speciali come il DUT con elementi sovrapposti predefinito STRING32_OVERLAPPING_DUT
Scambiare dati con dispositivi esterni tramite file, pagine HTML o tramite comandi di monitoraggio
In Control FPWIN Pro7, le seguenti due codifiche dei caratteri sono supportate in particolare tramite valori letterali stringa e tramite monitoraggio:
Codifica Latin-1, che è una codifica dei caratteri a un bit fissa secondo ISO 8859-1 (Latin-1) che abilita caratteri Unicode da 0x00 a 0xFF
Codifica UTF-8, che è una codifica dei caratteri multi-byte con caratteri che comprendono da 1 a 4 byte che abilitano tutti i caratteri Unicode da 0x00 a 0x10FFFF
Le codifiche dei caratteri Latin-1 e UTF-8 trattano i caratteri nell'intervallo da 0x00 a 0x7F in modo identico ai caratteri ASCII.
Andrebbe evitato l'uso misto di codifiche dei caratteri, per dettagli fare riferimento a "Come utilizzare la codifica dei caratteri UTF-8"
Valori letterali stringa
I valori letterali stringa contengono una sequenza di caratteri o di sequenze di caratteri di sequenze di caratteri di escape racchiuse tra caratteri con una virgoletta singola (').
I valori letterali stringa possono essere utilizzati qui:
Negli editor di dichiarazione per inizializzare una variabile del tipo di dato STRING
Nei corpi di programmazione come argomenti di ingresso
Sono disponibili i seguenti valori letterali stringa:
Valori letterali stringa codificati con Latin-1 che abilitano i caratteri Unicode da 0x00 a 0xFF
Valori letterali stringa senza tipo codificati con Latin-1 senza alcun prefisso come 'abc'. Questi generano un avviso quando contengono caratteri non-ASCII nell'intervallo da 0x80–0xFF come 'äöü'.
Esempi di valori letterali stringa senza tipo Latin-1:
Blocco Unicode
Valore letterale stringa senza tipo di Latin-1
Byte in rappresentazione esadecimale
Nota
Stringa vuota
''
''
Basic Latin (0x00–0x7F)
'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
'0-9'
' 30 2D 39'
'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
Latin-1 Supplement (0x80–0xFF)
'¥£©®'
' A5 A3 A9 AE'
Questo uso genera un messaggio di avviso.
'歨'
' B5 A1 BF'
'äöüß'
' E4 F6 FC DF'
'ÄÖÜ'
' C4 D6 DC'
Valori letterali stringa con tipo codificati con Latin-1 con il prefisso latin1# come latin1#'abc' o latin1#'äöü'
Esempi di valori letterali stringa con tipo Latin-1:
Blocco Unicode
Valore letterale stringa con tipo di Latin-1
Byte in rappresentazione esadecimale
Nota
Stringa vuota
latin1#''
''
Basic Latin (0x00–0x7F)
latin1#'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
latin1#'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
latin1#'0-9'
' 30 2D 39'
latin1#'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
Latin-1 Supplement (0x80–0xFF)
latin1#'¥£©®'
' A5 A3 A9 AE'
Questo uso non genera un messaggio di avviso.
latin1#'歨'
' B5 A1 BF'
latin1#'äöüß'
' E4 F6 FC DF'
latin1#'ÄÖÜ'
' C4 D6 DC'
Valori letterali stringa UTF-8
I valori letterali stringa codificati con UTF-8 con il prefisso utf8# come utf8#'abc', utf8#'äöü' o utf8#'ä+漢+🙏' sono in grado di codificare tutti i caratteri Unicode da 0x00 a 0x10FFFF in 1-4 byte.
Esempi di valori letterali stringa UTF-8
Byte per carattere
Blocco Unicode
Valore letterale stringa UTF-8
Byte in rappresentazione esadecimale
Stringa vuota
utf8#''
''
1
Basic Latin
utf8#'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
utf8#'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
utf8#'0-9'
' 30 2D 39'
utf8#'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
2
Latin-1 Supplement
utf8#'¥£©®'
' C2 A5 C2 A3 C2 A9 C2 AE'
utf8#'歨'
' C2 B5 C2 A1 C2 BF'
utf8#'äöüß'
' C3 A4 C3 B6 C3 BC C3 9F'
utf8#'ÄÖÜ'
' C3 84 C3 96 C3 9C'
Greco
utf8#'αβγ'
' CE B1 CE B2 CE B3'
3
CJK Hirakana
utf8#'ゖ'
' E3 82 96'
CJK Katakana
utf8#'ヺ'
' E3 83 BA'
CJK Unificato
utf8#'囆'
' E5 9B 86'
4
CJK Unificato
utf8#'𫜴'
' F0 AB 9C B4'
Emoticon
utf8#'🙏'
' F0 9F 99 8F'
Sequenze di carattere di Escape
Le sequenze di carattere di Escape possono essere utilizzate in valori letterali stringa di caratteri a 8 bit e in valori letterali stringa UTF-8.
Combinazioni di tre caratteri con il segno di dollaro all'inizio ($) seguito da due cifre esadecimali vanno interpretate come la rappresentazione esadecimale del codice di carattere di otto bit.
Valori letterali stringa
Byte in rappresentazione esadecimale
Nota
'$02$03'
utf8#'$02$03'
' 02 03'
STX, ETX
'$E5$9B$86'
utf8#'$E5$9B$86'
' E5 9B 86'
utf8#'囆'
'$F0$9F$99$8F'
utf8#'$F0$9F$99$8F'
' F0 9F 99 8F'
utf8#'🙏'
NOTASe si immette una sequenza di byte UTF-8 non valida in una stringa UTF-8, il risultato sarà una stringa UTF-8 non valida.
Esempio
Ingresso
utf8#'敬 敬$FE$FF敬 具' (' E6 95 AC FE FF E5 85 B7')
sString10 definita come STRING[10]
Operazione
sString10:= utf8#'敬敬$FE$FF敬具'Risultato
sString10: utf8?'敬敬þÿ敬具' (' E6 95 AC FE FF E5 85 B7')
Combinazioni di due caratteri con il segno di dollaro all'inizio vanno interpretate come indicato nella seguente tabella:
Valori letterali stringa
Byte in rappresentazione esadecimale
Nota
'$$'
utf8#'$$'
' 24'
Simbolo dollaro
'$''
utf8#'$''
' 27'
Virgoletta singola
'$L' o '$l'
utf8#'$L' o utf8#'$l'
' 0A'
Avanzamento linea
'$N' o '$n'
utf8#'$N' o utf8#'$n'
' 0D 0A'
Nuova riga
'$P' o '$p'
utf8#'$P' o utf8#'$p'
' 0C'
Avanzamento carta (pagina)
'$R' o '$r'
utf8#'$R' o utf8#'$r'
' 0D'
Ritorno a capo
'$T' o '$t'
utf8#'$T' o utf8#'$t'
' 09'
Scheda
Monitoraggio in base al tipo di stringa
Durante il monitoraggio, selezionare la rappresentazione di default per osservare i byte della stringa visualizzati correttamente secondo la codifica dei caratteri rilevata:
Tipo di stringa |
Prefisso |
Rappresentazione di default |
Rappresentazione esadecimale |
Esempio di programmazione editor ST |
|---|---|---|---|---|
Stringa codificata con Latin-1 |
- |
'a+b+c' |
' 61 2B 62 2B 63' |
CONCAT('a','+','b','+','c') |
latin1# |
latin1#'ä+¥+©' |
' E4 2B A5 2B A9' |
CONCAT('ä','+','¥','+','©') (usare valore letterale stringa con tipo di Latin-1 per evitare un messaggio di avviso) |
|
Stringa UTF-8 |
utf8# |
utf8#'ä+漢+🙏' |
' C3 A4 2B E6 BC A2 2B F0 9F 99 8F' |
CONCAT (utf8#'ä','+',utf8#'漢','+',utf8#'🙏') |
Stringa di tipo misto |
latin1utf8? |
latin1utf8?'ä+漢+🙏' |
' E4 2B E6 BC A2 2B F0 9F 99 8F' |
CONCAT ('ä','+',utf8#'漢','+',utf8#'🙏') |
Monitoraggio in Controllo dati in ingresso (EDM): Sono disponibili due rappresentazioni: default ed esadecimale.
Monitoraggio negli editor di programmazione: Rappresentazione di default nel corpo e nel tooltip, rappresentazione esadecimale solo nel tooltip.
Dichiarazione stringa
Per dichiarare tipi di variabile STRING nell'intestazione del POU usare la seguente sintassi:
STRING[n], ove n sta per il numero di byte
Il valore iniziale di default, p.es. per dichiarazioni di variabile nell'intestazione del POU o nella lista variabili globali è '', ovvero una stringa di caratteri vuota.
Stringhe non valide
Criterio per le stringhe non valide:
Il numero massimo di byte riservati per la stringa di caratteri è negativo o maggiore di 32767
Il numero attuale di byte contenuti nella stringa di caratteri è negativo o è maggiore di 32767
Il numero attuale di byte contenuti nelle stringhe di caratteri è maggiore del numero massimo di byte riservati per la stringa
Struttura di memoria interna di stringhe di caratteri nel PLC
Ciascun carattere della stringa di caratteri è memorizzato in un byte. Un'area di memoria di una stringa di caratteri è composta da un'intestazione (due word) e da una word per ogni due caratteri.
La prima word contiene il numero di byte riservati per la stringa di caratteri.
La seconda word contiene il numero effettivo di byte nella stringa di caratteri.
Le word successive contengono ciascuna due byte di caratteri della stringa.
Per riservare una determinata area di memoria per una STRING[n], specificare la lunghezza della stringa di caratteri con la seguente formula:
Capacità di memoria = 2 word (intestazione) + (n+1)/2 word (byte)
La memoria programma è organizzata in unità di word. Per questo motivo numeri di word sono sempre arrotondati per eccesso al numero intero seguente.
Offset word |
Byte alto |
Byte basso |
|---|---|---|
0 |
Numero massimo di byte riservati per la stringa di caratteri |
|
1 |
Numero attuale di byte contenuti nella stringa di caratteri |
|
2 |
Byte 2 |
Byte 1 |
3 |
Byte 4 |
Byte 3 |
4 |
Byte 6 |
Byte 5 |
... |
... |
... |
1+(n+1)/2 |
Byte n |
Byte n-1 |
Codifiche dei caratteri
Le codifiche dei caratteri Latin-1 e UTF-8 trattano i caratteri nell'intervallo da 0x00 a 0x7F in modo identico ai caratteri ASCII, come definito nei controlli C0 e basic Latin del blocco Unicode.
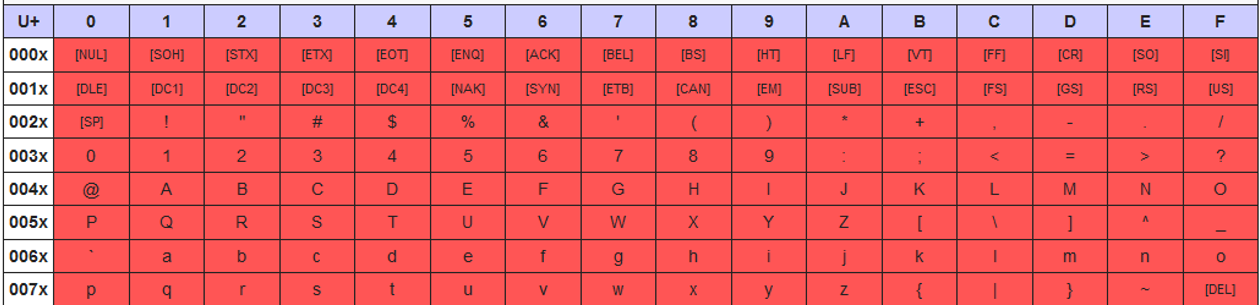
La codifica dei caratteri Latin-1 tratta i caratteri nell'intervallo da 0x80 a 0xFF come definito nei controlli C1 e Latin-1 supplement del blocco Unicode.
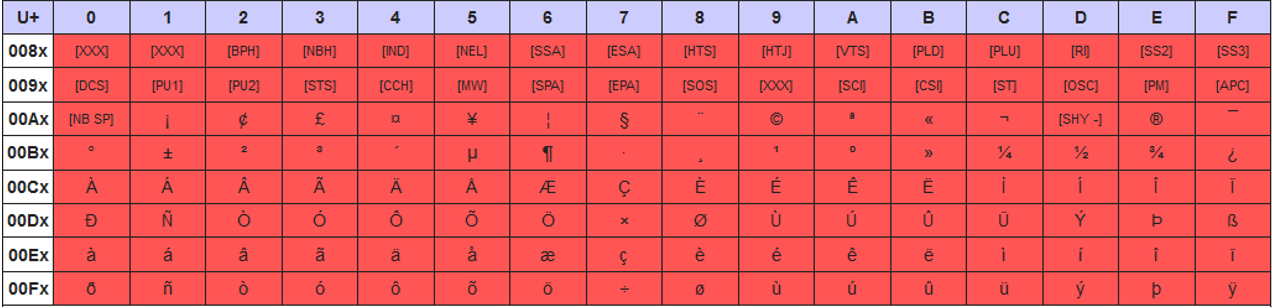
La codifica dei caratteri UTF-8 tratta i caratteri Unicode da 0x80 come:
Sequenza di byte UTF-8 (rappresentazione binaria)
Gamma Unicode
0xxxxxxx
0000 0000 – 0000 007F
110xxxxx 10xxxxxx
0000 0080 – 0000 07FF
1110xxxx 10xxxxxx 10xxxxxx
0000 0800 – 0000 FFFF
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
0001 0000 – 0010 FFFF
Come utilizzare la codifica dei caratteri UTF-8
Precauzioni
L'elaborazione corretta di caratteri UTF-8 attraverso istruzioni firmware non può essere garantita e dovrebbe essere verificata attentamente!
Note
Quando si lavora con le stringhe UTF-8, è fondamentale utilizzare esclusivamente stringhe UTF-8 ed evitare di mescolare stringhe UTF-8 e non UTF-8!
Quando si mescolano stringhe UTF-8 e stringhe non-UTF-8, le stringhe non-UTF-8 devono contenere solo caratteri nell'intervallo da 0x00 a 0x7F.
Funzioni come LEN, MID, LEFT; INSERT, DELETE, RIGHT sono orientate al byte. L'utilizzo con stringhe UTF-8, fa sì che i numeri di byte e le posizioni assunte dalla funzione non corrispondano ai numeri di carattere e alle posizioni della stringa UTF-8.
Esempio
Ingresso
utf8#'敬具' (' E6 95 AC E5 85 B7')
Operazione
LEN(utf8#'敬具')Risultato
6
Quando si applicano funzioni di stringa orientate al byte a stringhe UTF-8 con numeri di byte e posizioni che non corrispondono alla dimensione del byte e alla posizione iniziale del byte dei caratteri UTF-8, il risultato restituirà una stringa UTF-8 non valida.
Esempio
Ingresso
utf8#'敬具' (' E6 95 AC E5 85 B7')
Operazione
MID(IN := utf8#'敬具', L := 3, P := 4)Risultato
utf8#'具' (' E5 85 B7')
Operazione
MID(IN := utf8#'敬具', L := 3, P := 3)Risultato
'Œ$85' (' AC E5 85')
Se le stringhe di risultato UTF-8 sono più grandi delle stringhe di destinazione, il risultato può essere una stringa UTF-8 non valida.
Esempio
Ingresso
utf8#'敬具' (' E6 95 AC E5 85 B7')
sString5 definita come STRING[5]
Operazione
sString5:=utf8#'敬具'Risultato
sString5: utf8?'敬å$85' (' E6 95 AC E5 85')
I caratteri speciali nella gamma Unicode da 0x80 a 0xFF restituiscono risultati diversi a seconda che siano inseriti come stringhe di caratteri a 8 bit o come stringhe UTF-8.
Esempio
Ingresso
'ö' (' F6')
utf8#'ö' (' C3 B6')
Operazione
LEN('ö')Risultato
1
Operazione
LEN(utf8#'ö')Risultato
2
Operazione
'ö'= utf8#'ö'
Risultato
FALSE
La ricerca di una stringa di caratteri a 8 bit con caratteri nella gamma da 0x80 a 0xFF in una stringa UTF-8 e viceversa può portare a risultati inaspettati.
Esempio
Ingresso
utf8#'敬具' (' E6 95 AC E5 85 B7')
'å' (' E5')
Operazione
FIND(IN1 := utf8#'敬具', IN2 :='å')Risultato
4
Funzioni STRING con EN/ENO
Diagramma contatti (LD) e Diagramma Function Block (FBD)
Istruzioni STRING con contatti EN/ENO NON possono essere collegate l'una all'altra in LD ed FBD. Collegare prima le istruzioni STRING senza EN/ENO e aggiungere poi un'istruzione con EN/ENO nella posizione finale. L'ingresso abilitazione (EN) decide poi l'emissione del risultato complessivo.
Questa disposizione non è possibile:
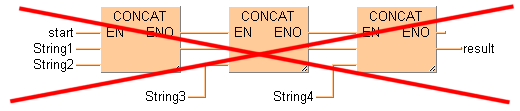
Questa disposizione è possibile:
