STRING
The data type STRING consists of two parts:
A header containing the maximum and the current number of bytes
A series (a string) of up to 32767 bytes depending on the memory size of the PLC which can contain any type of character encoding and even binary data
For details please refer to “Internal memory structure of strings on the PLC”.
Operation examples using variables of data type STRING:
Filling string variables by string literals or by conversion functions like WORD_TO_STRING, FP_FORMAT_STRING...
Using and manipulating string variables with string instructions like CONCAT, LEFT...
Arbitrarily accessing string variables via special address functions like Adr_OfVarOffs… or via special overlapping DUTs like the predefined overlapping DUT STRING32_OVERLAPPING_DUT
Exchanging data with external devices via files, HTML pages or via monitoring commands
In Control FPWIN Pro7, the following two character encodings are especially supported by string literals and by monitoring:
Latin-1 encoding, which is a fixed one-bit character encoding according to ISO 8859-1 (Latin-1) allowing Unicode characters from 0x00–0xFF
UTF-8 encoding, which is a multi-byte character encoding with characters comprising 1 to 4 bytes allowing all Unicode characters from 0x00–0x10FFFF
Latin-1 and UTF-8 character encodings treat the characters in the range of 0x00–0x7F identically as ASCII characters.
Mixing the character encodings should be prevented, for details please refer to "How to use UTF-8 character encoding"
String literals
String literals contain a sequence of characters of escape sequences enclosed in single quote characters (').
String literals can be used here:
In the declaration editors to initialize a variable of data type STRING
In the programming bodies as input arguments
The following string literals are available:
Latin-1 encoded string literals allowing Unicode characters from 0x00–0xFF
Untyped Latin-1 encoded string literals without any prefix like 'abc'. They generate a warning when they contain non-ASCII characters in the range from 0x80–0xFF such as 'äöü'.
Examples of untyped Latin-1 string literals:
Unicode block
Untyped Latin-1 string literal
Bytes in hex representation
Remark
Empty string
''
''
Basic Latin (0x00–0x7F)
'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
'0-9'
' 30 2D 39'
'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
Latin-1 Supplement (0x80–0xFF)
'¥£©®'
' A5 A3 A9 AE'
This usage generates a warning message.
'歨'
' B5 A1 BF'
'äöüß'
' E4 F6 FC DF'
'ÄÖÜ'
' C4 D6 DC'
Typed Latin-1 encoded string literals with the prefix latin1# like latin1#'abc' or latin1#'äöü'
Examples of typed Latin-1 string literals:
Unicode block
Typed Latin-1 string literal
Bytes in hex representation
Remark
Empty string
latin1#''
''
Basic Latin (0x00–0x7F)
latin1#'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
latin1#'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
latin1#'0-9'
' 30 2D 39'
latin1#'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
Latin-1 Supplement (0x80–0xFF)
latin1#'¥£©®'
' A5 A3 A9 AE'
This usage does not generate a warning message.
latin1#'歨'
' B5 A1 BF'
latin1#'äöüß'
' E4 F6 FC DF'
latin1#'ÄÖÜ'
' C4 D6 DC'
UTF-8 string literals
UTF-8 encoded string literals with the prefix utf8# like utf8#'abc', utf8#'äöü' or utf8#'ä+漢+🙏' are able to encode all Unicode characters from 0x00–0x10FFFF in 1 to 4 bytes.
Examples of UTF-8 string literals
Bytes per character
Unicode block
UTF-8 string literal
Bytes in hex representation
Empty string
utf8#''
''
1
Basic Latin
utf8#'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
utf8#'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
utf8#'0-9'
' 30 2D 39'
utf8#'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
2
Latin-1 Supplement
utf8#'¥£©®'
' C2 A5 C2 A3 C2 A9 C2 AE'
utf8#'歨'
' C2 B5 C2 A1 C2 BF'
utf8#'äöüß'
' C3 A4 C3 B6 C3 BC C3 9F'
utf8#'ÄÖÜ'
' C3 84 C3 96 C3 9C'
Greek
utf8#'αβγ'
' CE B1 CE B2 CE B3'
3
CJK Hirakana
utf8#'ゖ'
' E3 82 96'
CJK Katakana
utf8#'ヺ'
' E3 83 BA'
CJK Unified
utf8#'囆'
' E5 9B 86'
4
CJK Unified
utf8#'𫜴'
' F0 AB 9C B4'
Emoticon
utf8#'🙏'
' F0 9F 99 8F'
Escape-character sequences
Escape-character sequences can be used in 8-bit character string literals and in UTF-8 string literals.
Three-character combinations of the dollar sign ($) followed by two hexadecimal digits are to be interpreted as the hexadecimal representation of the eight-bit character code.
String literal
Bytes in hex representation
Remark
'$02$03'
utf8#'$02$03'
' 02 03'
STX, ETX
'$E5$9B$86'
utf8#'$E5$9B$86'
' E5 9B 86'
utf8#'囆'
'$F0$9F$99$8F'
utf8#'$F0$9F$99$8F'
' F0 9F 99 8F'
utf8#'🙏'
NOTEIf you enter an invalid UTF-8 byte sequence in an UTF-8 string, the result will be an invalid UTF-8 string.
Example
Input
utf8#'敬 敬$FE$FF敬 具' (' E6 95 AC FE FF E5 85 B7')
sString10 defined as STRING[10]
Operation
sString10:= utf8#'敬敬$FE$FF敬具'Result
sString10: utf8?'敬敬þÿ敬具' (' E6 95 AC FE FF E5 85 B7')
Two-character combinations beginning with the dollar sign are to be interpreted as shown in the table:
String literal
Bytes in hex representation
Remark
'$$'
utf8#'$$'
' 24'
Dollar sign
'$''
utf8#'$''
' 27'
Single quote
'$L' or '$l'
utf8#'$L' or utf8#'$l'
' 0A'
Line feed
'$N' or '$n'
utf8#'$N' or utf8#'$n'
' 0D 0A'
New line
'$P' or '$p'
utf8#'$P' or utf8#'$p'
' 0C'
Form feed (page)
'$R' or '$r'
utf8#'$R' or utf8#'$r'
' 0D'
Carriage return
'$T' or '$t'
utf8#'$T' or utf8#'$t'
' 09'
Tab
Monitoring depending on string type
During monitoring, select the default representation to see the string bytes displayed correctly according to the detected character encoding:
Type of a string |
Prefix |
Default representation |
Hexadecimal representation |
Programming example ST editor |
|---|---|---|---|---|
Latin-1 encoded string |
- |
'a+b+c' |
' 61 2B 62 2B 63' |
CONCAT('a','+','b','+','c') |
latin1# |
latin1#'ä+¥+©' |
' E4 2B A5 2B A9' |
CONCAT('ä','+','¥','+','©') (use typed Latin-1 string literal to avoid a warning message) |
|
UTF-8 string |
utf8# |
utf8#'ä+漢+🙏' |
' C3 A4 2B E6 BC A2 2B F0 9F 99 8F' |
CONCAT (utf8#'ä','+',utf8#'漢','+',utf8#'🙏') |
Mixed type string |
latin1utf8? |
latin1utf8?'ä+漢+🙏' |
' E4 2B E6 BC A2 2B F0 9F 99 8F' |
CONCAT ('ä','+',utf8#'漢','+',utf8#'🙏') |
Monitoring in Entry data monitor (EDM): Two representations are available: default and hexadecimal.
Monitoring in programming editors: Default representation in the body and in the tool tip, hexadecimal representation only in the tool tip.
String declaration
To declare STRING type variables in the POU header use the following syntax:
STRING[n], where n = number of bytes
The default initial value, e.g. for variable declarations in the POU header or global variable list, is '', i.e. an empty string.
Invalid strings
Criterion for invalid strings:
The maximum number of bytes reserved for the string characters is negative or greater than 32767
The current number of bytes contained in the string characters is negative or greater than 32767
The current number of bytes contained the string characters is greater than the maximum number of bytes reserved for the string
Internal memory structure of strings on the PLC
Each character of the string is stored in one byte. A string's memory area consists of a header (two words) and one word for every two characters.
The first word contains the number of bytes reserved for the string.
The second word contains the current number of bytes in the string.
Subsequent words contain two bytes of the string characters each.
To reserve a certain memory area for a STRING[n], specify the string length using the following formula:
Memory size = 2 words (header) + (n+1)/2 words (bytes)
The memory is organized in word units. Therefore, word numbers are always rounded up to the next whole number.
Word offset |
High byte |
Low byte |
|---|---|---|
0 |
Maximum number of bytes reserved for the string characters |
|
1 |
Current number of bytes contained in the string characters |
|
2 |
Byte 2 |
Byte 1 |
3 |
Byte 4 |
Byte 3 |
4 |
Byte 6 |
Byte 5 |
... |
... |
... |
1+(n+1)/2 |
Byte n |
Byte n-1 |
Character encodings
Latin-1 and UTF-8 character encodings treat the characters in the range of 0x00–0x7F identically as ASCII characters as defined in the Unicode block C0 controls and basic Latin.
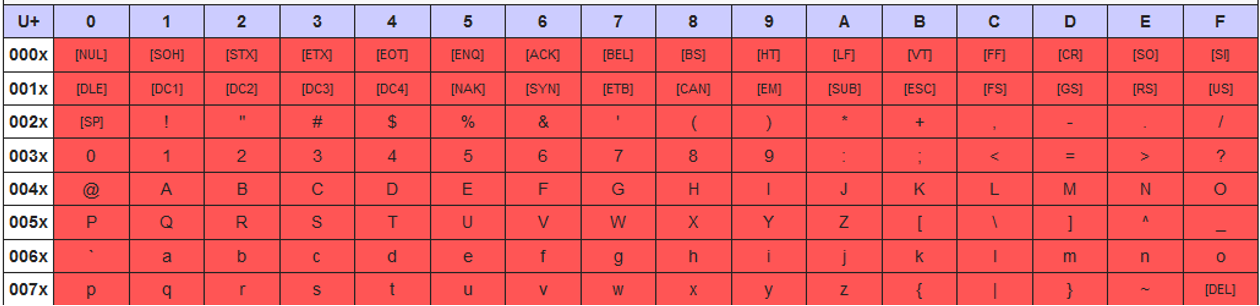
Latin-1 character encoding treats the characters in the range of 0x80–0xFF as defined in Unicode block C1 controls and Latin-1 supplement.
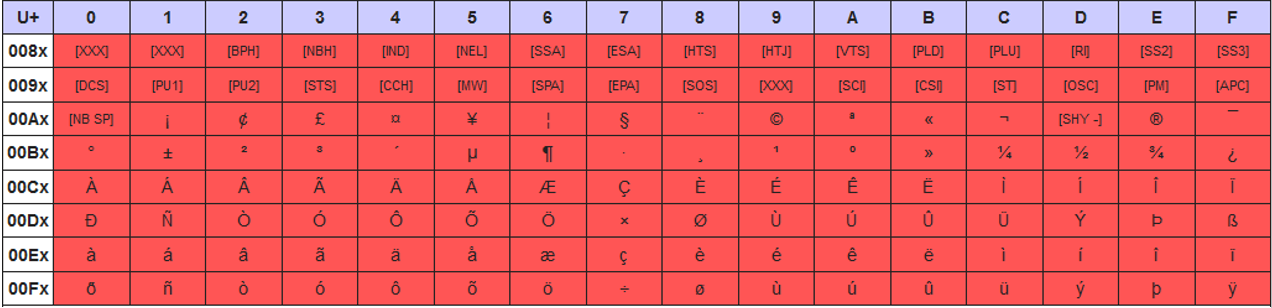
UTF-8 character encoding treats the Unicode characters from 0x80 as:
UTF-8 byte sequence (binary representation)
Unicode range
0xxxxxxx
0000 0000 – 0000 007F
110xxxxx 10xxxxxx
0000 0080 – 0000 07FF
1110xxxx 10xxxxxx 10xxxxxx
0000 0800 – 0000 FFFF
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
0001 0000 – 0010 FFFF
How to use UTF-8 character encoding
Precautions
The correct handling of UTF-8 character encoding by firmware instructions cannot be guaranteed and must be checked explicitly and in detail!
Remarks
When working with UTF-8 strings, it is highly recommended to use only UTF-8 strings and to avoid mixing UTF-8 strings and non-UTF-8 strings!
When mixing UTF-8 strings and non-UTF-8 strings, the non-UTF-8 strings should contain only characters in the range from 0x00–0x7F.
Functions like LEN, MID, LEFT; INSERT, DELETE, RIGHT are byte-oriented. When they are used with UTF-8 strings, it is possible that the byte numbers and positions assumed by the function do not correspond to the character numbers and positions of the UTF-8 string.
Example
Input
utf8#'敬具' (' E6 95 AC E5 85 B7')
Operation
LEN(utf8#'敬具')Result
6
When applying byte-oriented string functions to UTF-8 strings with byte numbers and positions which do not correspond to the byte size and the start byte position of UTF-8 characters, the result will be an invalid UTF-8 string.
Example
Input
utf8#'敬具' (' E6 95 AC E5 85 B7')
Operation
MID(IN := utf8#'敬具', L := 3, P := 4)Result
utf8#'具' (' E5 85 B7')
Operation
MID(IN := utf8#'敬具', L := 3, P := 3)Result
'Œ$85' (' AC E5 85')
If UTF-8 result strings are larger than the target strings, the result can be an invalid UTF-8 string.
Example
Input
utf8#'敬具' (' E6 95 AC E5 85 B7')
sString5 defined as STRING[5]
Operation
sString5:=utf8#'敬具'Result
sString5: utf8?'敬å$85' (' E6 95 AC E5 85')
Special characters in the Unicode range from 0x80–0xFF yield different results depending on whether they are entered as 8-bit character strings or as UTF-8 strings.
Example
Input
'ö' (' F6')
utf8#'ö' (' C3 B6')
Operation
LEN('ö')Result
1
Operation
LEN(utf8#'ö')Result
2
Operation
'ö'= utf8#'ö'
Result
FALSE
Searching an 8-bit character string with characters in the range from 0x80–0xFF in a UTF-8 string and vice versa may lead to unexpected results.
Example
Input
utf8#'敬具' (' E6 95 AC E5 85 B7')
'å' (' E5')
Operation
FIND(IN1 := utf8#'敬具', IN2 :='å')Result
4
STRING functions with EN/ENO
Ladder diagram (LD) and function block diagram (FBD)
STRING instructions with enable input (EN) and enable output (ENO) contacts may NOT be connected to each other in LD and FBD. First connect the STRING instructions without EN/ENO and then add an instruction with EN/ENO in the final position. The enable input (EN) then controls the output of the overall result.
This arrangement is not possible:
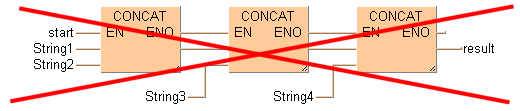
This arrangement is possible:
