STRING
データ型STRINGは、次の2つの部分で構成されています。
最大バイト数と現在のバイト数を含むヘッダー
PLCのメモリサイズに応じて最大32767バイトのシリーズ(文字列)。任意のタイプの文字エンコーディングとバイナリデータを含めることができます
詳細については、「PLC内部メモリの文字列の構造」を参照してください。
データ型STRINGの変数を使用した操作例:
文字列リテラルによる文字列変数の入力、またはWORD_TO_STRING、FP_FORMAT_STRINGなどの変換関数による文字列変数の入力
CONCAT、LEFTなどの文字列命令による文字列変数の使用および操作
Adr_OfVarOffsなどの特殊なアドレス関数を介した文字列変数、または事前に定義された重複するDUTSTRING32_OVERLAPPING_DUTなどの特別な重複するDUTを介した文字列変数への任意のアクセス
ファイルまたはHTMLページ、あるいはモニタリングコマンドを介した外部デバイスとのデータ交換
Control FPWIN Pro7では、特に文字列リテラルおよびモニタリングによって、次の2つの文字エンコーディングがサポートされています。
ラテン1エンコーディング。ISO 8859-1(ラテン1)に準拠した固定の1ビット文字エンコーディングで、0x00~0xFFのUnicode文字を使用できます
UTF-8エンコーディング。1~4バイトで構成される文字を含むマルチバイト文字エンコーディングで、0x00–0x10FFFFのすべてのUnicode文字を使用できます
ラテン1およびUTF-8文字エンコーディングでは、0x00~0x7Fの範囲内の文字はASCII文字と同様に処理されます。
文字エンコーディングを混在させないようにする必要があります。詳細については、「UTF-8文字エンコーディングの使用方法」を参照してください。
文字列リテラル
文字列リテラルには、シングルクォーテーション(')で囲まれたエスケープ文字列が含まれます。
文字列リテラルは、次の場所に使用できます。
宣言エディタでデータ型STRINGの変数を初期化するとき
プログラムのボディの入力引数
次の文字列リテラルを使用できます。
ラテン1でエンコードされた文字列リテラル。0x00–0xFFのUnicode文字を使用できます。
型指定なしラテン1エンコードされた文字列リテラル('abc'などのプレフィックスなし)。'äöü'.など、0x80~0xFFの範囲のASCII以外の文字が含まれている場合は、警告が生成されます。
型指定なしラテン1文字列リテラルの例:
Unicodeブロック
型指定なしラテン1文字列リテラル
16進表現でのバイト
備考
空の文字列
''
''
基本ラテン文字(0x00–0x7F)
'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
'0-9'
' 30 2D 39'
'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
ラテン1補助(0x80–0xFF)
'¥£©®'
' A5 A3 A9 AE'
これを使用すると、警告メッセージが生成されます。
'歨'
' B5 A1 BF'
'äöüß'
' E4 F6 FC DF'
'ÄÖÜ'
' C4 D6 DC'
型指定されたラテン1エンコード文字列リテラルで、プレフィックスlatin1#がlatin1#'abc'やlatin1#'äöü'などのもの
型指定されたラテン1文字列リテラルの例:
Unicodeブロック
型指定されたラテン1文字列リテラル
16進表現でのバイト
備考
空の文字列
latin1#''
''
基本ラテン文字(0x00–0x7F)
latin1#'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
latin1#'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
latin1#'0-9'
' 30 2D 39'
latin1#'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
ラテン1補助(0x80–0xFF)
latin1#'¥£©®'
' A5 A3 A9 AE'
この場合、警告メッセージは表示されません。
latin1#'歨'
' B5 A1 BF'
latin1#'äöüß'
' E4 F6 FC DF'
latin1#'ÄÖÜ'
' C4 D6 DC'
UTF-8文字列リテラル
プレフィックスutf8#がutf8#'abc'、utf8#'äöü'、またはutf8#'ä+漢+🙏'などで構成されるUTF-8でエンコードされた文字列リテラルは、0x00~0x10FFFFのすべてのUnicode文字を1から4バイトでエンコードできます。
UTF-8文字列リテラルの例
1文字あたりのバイト数
Unicodeブロック
UTF-8文字列リテラル
16進表現でのバイト
空の文字列
utf8#''
''
1
基本ラテン文字
utf8#'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
utf8#'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
utf8#'0-9'
' 30 2D 39'
utf8#'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
2
ラテン1補助
utf8#'¥£©®'
' C2 A5 C2 A3 C2 A9 C2 AE'
utf8#'歨'
' C2 B5 C2 A1 C2 BF'
utf8#'äöüß'
' C3 A4 C3 B6 C3 BC C3 9F'
utf8#'ÄÖÜ'
' C3 84 C3 96 C3 9C'
ギリシャ文字
utf8#'αβγ'
' CE B1 CE B2 CE B3'
3
CJK平仮名
utf8#'ゖ'
' E3 82 96'
CJKカタカナ
utf8#'ヺ'
' E3 83 BA'
CJK統合
utf8#'囆'
' E5 9B 86'
4
CJK統合
utf8#'𫜴'
' F0 AB 9C B4'
顔文字
utf8#'🙏'
' F0 9F 99 8F'
エスケープ文字列
エスケープ文字列は8ビットの文字列リテラルおよびUTF-8文字列リテラルで使用できます。
ドル記号($)の後ろに2桁の16進数を付加した3文字1組の文字列は、8ビット文字コードの16進表記として解釈されます。
文字列リテラル
16進表現でのバイト
備考
'$02$03'
utf8#'$02$03'
' 02 03'
STX, ETX
'$E5$9B$86'
utf8#'$E5$9B$86'
' E5 9B 86'
utf8#'囆'
'$F0$9F$99$8F'
utf8#'$F0$9F$99$8F'
' F0 9F 99 8F'
utf8#'🙏'
注記無効なUTF-8バイト列をUTF-8文字列に入力すると、結果は無効なUTF-8文字列になります。
例
入力
utf8#'敬 敬$FE$FF敬 具' (' E6 95 AC FE FF E5 85 B7')
sString10をSTRING[10]として定義
操作
sString10:= utf8#'敬敬$FE$FF敬具'結果
sString10: utf8?'敬敬þÿ敬具' (' E6 95 AC FE FF E5 85 B7')
ドル記号($)で始まる2文字1組の文字列は、下表のように解釈されます。
文字列リテラル
16進表現でのバイト
備考
'$$'
utf8#'$$'
' 24'
ドル記号
'$''
utf8#'$''
' 27'
シングルクォーテーション
'$L'または'$l'
utf8#'$L'またはutf8#'$l'
' 0A'
ラインフィード
'$N'または'$n'
utf8#'$N'またはutf8#'$n'
' 0D 0A'
ニューライン
'$P'または'$p'
utf8#'$P'またはutf8#'$p'
' 0C'
改ページ
'$R'または'$r'
utf8#'$R'またはutf8#'$r'
' 0D'
改行
'$T'または'$t'
utf8#'$T'またはutf8#'$t'
' 09'
タブ
文字列型別のモニタリング
モニタリング中に、デフォルトの表現を選択して、検出された文字エンコーディングに従って文字列のバイトが正しく表示されるようにします。
文字列の種類 |
プレフィックス |
デフォルト表現 |
16進表現 |
STエディタのプログラミング例 |
|---|---|---|---|---|
ラテン1でエンコードされた文字列 |
- |
'a+b+c' |
' 61 2B 62 2B 63' |
CONCAT('a','+','b','+','c') |
latin1# |
latin1#'ä+¥+©' |
' E4 2B A5 2B A9' |
CONCAT('ä','+','¥','+','©') (警告メッセージを回避するには、型指定されたラテン1文字列リテラルを使用します) |
|
UTF-8文字列 |
utf8# |
utf8#'ä+漢+🙏' |
' C3 A4 2B E6 BC A2 2B F0 9F 99 8F' |
CONCAT (utf8#'ä','+',utf8#'漢','+',utf8#'🙏') |
混合型文字列 |
latin1utf8? |
latin1utf8?'ä+漢+🙏' |
' E4 2B E6 BC A2 2B F0 9F 99 8F' |
CONCAT ('ä','+',utf8#'漢','+',utf8#'🙏') |
「ユーザモニタ」(EDM)でのモニタリング:デフォルトと16進の2つの表現が可能です。
プログラミングエディタでのモニタリング:デフォルト表現はボディとツールチップ、16進表現はツールチップのみです。
文字列の宣言
POUヘッダーでSTRING型の変数を宣言するには、以下の文法を使用します。
STRING[n]、n=バイト数
例えば、POUヘッダーやグローバル変数リストでの変数宣言のデフォルト値は''(空の文字列)です。
無効な文字列
無効な文字列の基準は以下のとおりです:
文字列用に確保される最大バイト数が負の場合や32767より大きい場合
文字列に含まれる現在のバイト数が負の場合や32767より大きい場合
文字列に含まれる現在のバイト数が文字列用に確保されている最大バイト数より大きい場合
PLC内部メモリの文字列の構造
それぞれの文字は、1バイト単位で格納されます。文字列のメモリエリアは、ヘッダー(2ワード)と2文字ごとに1ワードで構成されています。
最初のワードには、文字列用に確保されているバイト数が格納されます。
2ワード目には、現在格納されているバイト数が格納されます。
その後のワードには、1文字あたり2バイトが格納されます。
STRING[n]用に特定のメモリエリアを確保するには、次式を使用して文字列の長さを指定します。
メモリサイズ = 2ワード(ヘッダー) + (n+1)/2ワード(バイト)
メモリはワード単位で構成されます。このため、ワード数は常に次の整数に四捨五入されます。
ワードオフセット |
上位バイト |
下位バイト |
|---|---|---|
0 |
文字列用に確保される最大のバイト数 |
|
1 |
文字列に含まれる現在のバイト数 |
|
2 |
バイト2 |
バイト1 |
3 |
バイト4 |
バイト3 |
4 |
バイト6 |
バイト5 |
... |
... |
... |
1+(n+1)/2 |
バイトn |
バイトn-1 |
文字エンコーディング
ラテン1およびUTF-8文字エンコーディングでは、0x00~0x7Fの範囲の文字はUnicodeブロックC0コントロールおよび基本的なラテン文字で定義されているASCII文字と同様に処理されます。
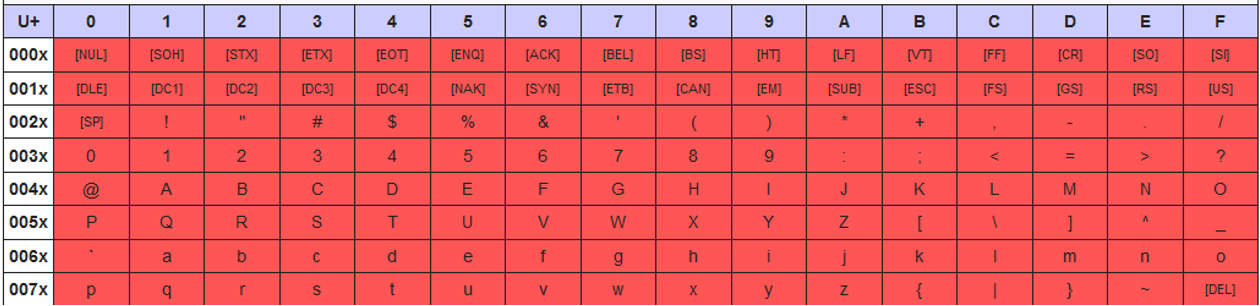
ラテン1文字エンコーディングでは、0x80~0xFFの範囲の文字はUnicodeブロックC1コントロールおよびラテン1補助で定義されているのと同様に処理されます。
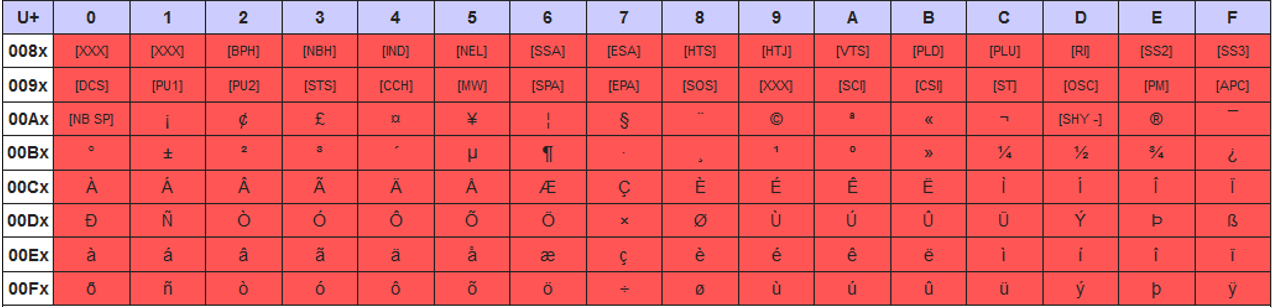
UTF-8文字エンコーディングでは、0x80のUnicode文字が次のように処理されます。
UTF-8バイト列(バイナリ表現)
Unicodeの範囲
0xxxxxxx
0000 0000 – 0000 007F
110xxxxx 10xxxxxx
0000 0080 – 0000 07FF
1110xxxx 10xxxxxx 10xxxxxx
0000 0800 – 0000 FFFF
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
0001 0000 – 0010 FFFF
UTF-8文字エンコーディングの使用方法
注意事項
ファームウェア命令でUTF-8文字エンコーディングを正しく処理することは保証されないため、明示的に詳しく確認する必要があります。
解説
UTF-8文字列を使用する場合は、UTF-8文字列のみを使用し、UTF-8文字列と非UTF-8文字列を一緒に使用しないことをお勧めします。
UTF-8文字列と非UTF-8文字列を一緒に使用する場合は、0x00~0x7F.の範囲の文字を含む非UTF-8文字列のみを使用してください。
LEN、MID、 LEFT、INSERT、DELETE、RIGHTは、バイト指向のファンクションです。これらをUTF-8文字列とともに使用すると、ファンクションが想定するバイト番号や位置がUTF-8文字列の文字番号や位置と一致しない可能性があります。
例
入力
utf8#'敬具' (' E6 95 AC E5 85 B7')
操作
LEN(utf8#'敬具')結果
6
バイト指向の文字列ファンクションをUTF-8文字列に適用する場合、バイト番号や位置がUTF-8文字のバイトサイズや開始バイト位置と一致しないと、結果が無効なUTF-8文字列になります。
例
入力
utf8#'敬具' (' E6 95 AC E5 85 B7')
操作
MID(IN := utf8#'敬具', L := 3, P := 4)結果
utf8#'具' (' E5 85 B7')
操作
MID(IN := utf8#'敬具', L := 3, P := 3)結果
'Œ$85' (' AC E5 85')
UTF-8結果文字列がターゲット文字列より大きい場合、結果は無効なUTF-8文字列である可能性があります。
例
入力
utf8#'敬具' (' E6 95 AC E5 85 B7')
sString5をSTRING[5]として定義
操作
sString5:=utf8#'敬具'結果
sString5: utf8?'敬å$85' (' E6 95 AC E5 85')
Unicodeの範囲が0x80~0xFFの特殊文字では、それが8ビット文字列として入力されたか、またはUTF-8文字列として入力されたかによって、結果が異なります。
例
入力
'ö' (' F6')
utf8#'ö' (' C3 B6')
操作
LEN('ö')結果
1
操作
LEN(utf8#'ö')結果
2
操作
'ö'= utf8#'ö'
結果
FALSE
UTF-8文字列で範囲が0x80~0xFFの文字を含む8ビット文字列を検索した場合、またはその逆の場合も、期待した結果を得られない可能性があります。
例
入力
utf8#'敬具' (' E6 95 AC E5 85 B7')
'å' (' E5')
操作
FIND(IN1 := utf8#'敬具', IN2 :='å')結果
4
EN/ENO付の文字列ファンクション
ラダーダイアグラム(LD)/ファンクションブロックダイアグラム(FBD)
LDまたはFBD内では、イネーブル入力(EN)とイネーブル出力(ENO)付の文字列命令を互いに接続することはできません。まず、EN/ENOのない文字列命令を接続し、それからEN/ENO付命令を最後に配置して使用します。イネーブル入力(EN)によって、最終的な演算結果の出力が制御されます。
次のように接続することはできません
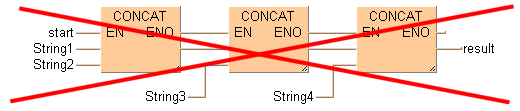
次のように接続することはできます
