STRING
데이터 형식 STRING은 다음과 같은 두 가지 부분으로 구성됩니다.
최대 바이트 수와 현재 바이트 수를 포함하는 헤더
PLC의 메모리 크기에 따라 최대 32767바이트의 시리즈(문자열)(모든 유형의 문자 인코딩과 이진 데이터를 포함할 수 있음)
자세한 내용은 "PLC의 문자열 내부 메모리 구조"를 참조하십시오.
STRING 데이터 형식의 변수를 사용하는 연산 예
문자열 리터럴 또는 변환 펑션(예: WORD_TO_STRING, FP_FORMAT_STRING)과 같은 문자열 변수로 채우기
문자열 명령(예: CONCAT, LEFT.)으로 문자열 변수 사용 및 조작
특수 어드레스 펑션(예: Adr_OfVarOffs 등) 또는 특수 중첩 DUT(예: 사전 정의된 중첩 DUT STRING32_OVERLAPPING_DUT)를 통해 문자열 변수에 임의 액세스
파일, HTML 페이지 또는 모니터링 명령을 통해 외부 장치와 데이터 교환
Control FPWIN Pro7에서는 특히 다음 두 문자 인코딩이 문자열 리터럴과 모니터링에서 지원됩니다.
Latin-1 인코딩 - ISO 8859-1(Latin-1)에 기반한 고정된 1비트 문자 인코딩으로, 0x00~0xFF 범위의 유니코드 문자 허용
UTF-8 인코딩 - 1~4바이트 문자로 구성된 멀티바이트 문자 인코딩으로, 0x00~0x10FFFF 범위의 모든 유니코드 문자 허용
Latin-1 및 UTF-8 문자 인코딩은 0x00~0x7F 범위의 문자를 ASCII 문자와 동일하게 처리합니다.
문자 인코딩을 혼합하여 사용하지 않아야 합니다. 자세한 내용은 "UTF-8 문자 인코딩 사용 방법"을 참조하십시오.
문자열 리터럴
문자열 리터럴에는 작은 따옴표 문자( ')로 묶인 일련의 이스케이프 시퀀스 문자가 포함됩니다.
문자열 리터럴은 다음에서 사용할 수 있습니다.
선언 에디터에서 STRING 데이터 형식의 변수를 초기화하기 위해
프로그래밍 바디에서 입력 인수로
다음 문자열 리터럴을 사용할 수 있습니다.
Latin-1로 인코딩된 문자열 리터럴(0x00~0xFF 범위의 유니코드 문자 허용)
형식 없는 Latin-1로 인코딩된 문자열 리터럴('abc'와 같은 접두사 없음). 0x80~0xFF 범위의 비 ASCII 문자(예: 'äöü')를 포함하면 경고가 생성됩니다.
형식 없는 Latin-1 문자열 리터럴의 예:
유니코드 블록
형식 없는 Latin-1 문자열 리터럴
16진수 표시의 바이트
주석
빈 문자열
''
''
기본 라틴(0x00–0x7F)
'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
'0-9'
' 30 2D 39'
'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
Latin-1 Supplement (0x80–0xFF)
'¥£©®'
' A5 A3 A9 AE'
이렇게 사용하면 경고 메시지가 생성됩니다.
'歨'
' B5 A1 BF'
'äöüß'
' E4 F6 FC DF'
'ÄÖÜ'
' C4 D6 DC'
형식화된 Latin-1로 인코딩된 문자열 리터럴(latin1#'abc' 또는 latin1#'äöü' 같이 접두사 latin1# 포함)
형식화된 Latin-1 문자열 리터럴의 예:
유니코드 블록
형식화된 Latin-1 문자열 리터럴
16진수 표시의 바이트
주석
빈 문자열
latin1#''
''
기본 라틴(0x00–0x7F)
latin1#'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
latin1#'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
latin1#'0-9'
' 30 2D 39'
latin1#'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
Latin-1 Supplement (0x80–0xFF)
latin1#'¥£©®'
' A5 A3 A9 AE'
이렇게 사용하면 경고 메시지가 생성되지 않습니다.
latin1#'歨'
' B5 A1 BF'
latin1#'äöüß'
' E4 F6 FC DF'
latin1#'ÄÖÜ'
' C4 D6 DC'
UTF-8 문자열 리터럴
UTF-8로 인코딩된 문자열 리터럴(utf8#'abc', utf8#'äöü' 또는 utf8#'ä+漢+🙏' 같은 utf8# 접두사는 1~4바이트 크기의 0x00~0x10FFFF 범위에 포함된 모든 유니코드 문자를 인코딩할 수 있음).
UTF-8 문자열 리터럴 예
문자당 바이트
유니코드 블록
UTF-8 문자열 리터럴
16진수 표시의 바이트
빈 문자열
utf8#''
''
1
기본 라틴
utf8#'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
utf8#'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
utf8#'0-9'
' 30 2D 39'
utf8#'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
2
Latin-1 Supplement
utf8#'¥£©®'
' C2 A5 C2 A3 C2 A9 C2 AE'
utf8#'歨'
' C2 B5 C2 A1 C2 BF'
utf8#'äöüß'
' C3 A4 C3 B6 C3 BC C3 9F'
utf8#'ÄÖÜ'
' C3 84 C3 96 C3 9C'
그리스어
utf8#'αβγ'
' CE B1 CE B2 CE B3'
3
CJK 히라가나
utf8#'ゖ'
' E3 82 96'
CJK 가타카나
utf8#'ヺ'
' E3 83 BA'
CJK 통합
utf8#'囆'
' E5 9B 86'
4
CJK 통합
utf8#'𫜴'
' F0 AB 9C B4'
이모티콘
utf8#'🙏'
' F0 9F 99 8F'
이스케이프 문자 시퀀스
이스케이프 문자 시퀀스는 8비트 문자열 리터럴 및 UTF-8 문자열 리터럴에서 사용할 수 있습니다.
16진수 두 개 다음에 오는 달러 기호($)와 결합된 3문자는 8비트 문자 코드의 16진수 표현으로 해석됩니다.
문자열 리터럴
16진수 표시의 바이트
주석
'$02$03'
utf8#'$02$03'
' 02 03'
STX, ETX
'$E5$9B$86'
utf8#'$E5$9B$86'
' E5 9B 86'
utf8#'囆'
'$F0$9F$99$8F'
utf8#'$F0$9F$99$8F'
' F0 9F 99 8F'
utf8#'🙏'
주석UTF-8 문자열에 유효하지 않은 UTF-8 바이트 시퀀스를 입력하면 결과는 유효하지 않은 UTF-8 문자열이 됩니다.
예
입력
utf8#'敬 敬$FE$FF敬 具' (' E6 95 AC FE FF E5 85 B7')
STRING[10]으로 정의된 sString10
동작
sString10:= utf8#'敬敬$FE$FF敬具'결과
sString10: utf8?'敬敬þÿ敬具' (' E6 95 AC FE FF E5 85 B7')
앞에 달러 기호와 결합된 2문자는 표와 같이 해석되어야 합니다.
문자열 리터럴
16진수 표시의 바이트
주석
'$$'
utf8#'$$'
' 24'
달러 기호
'$''
utf8#'$''
' 27'
작은따옴표
'$L' 또는 '$l'
utf8#'$L' 또는 utf8#'$l'
' 0A'
줄바꿈
'$N' 또는 '$n'
utf8#'$N' 또는 utf8#'$n'
' 0D 0A'
새 줄
'$P' 또는 '$p'
utf8#'$P' 또는 utf8#'$p'
' 0C'
용지 공급(페이지)
'$R' 또는 '$r'
utf8#'$R' 또는 utf8#'$r'
' 0D'
캐리지 리턴
'$T' 또는 '$t'
utf8#'$T' 또는 utf8#'$t'
' 09'
탭
문자열 유형에 따른 모니터링
모니터링 중에 기본 표현을 선택하여 감지된 문자 인코딩에 따라 올바르게 표시되는 문자열 바이트를 확인합니다.
문자열 유형 |
접두사 |
기본 표현 |
16진수 표현 |
프로그래밍 예제 ST 에디터 |
|---|---|---|---|---|
Latin-1로 인코딩된 문자열 |
- |
'a+b+c' |
' 61 2B 62 2B 63' |
CONCAT('a','+','b','+','c') |
latin1# |
latin1#'ä+¥+©' |
' E4 2B A5 2B A9' |
CONCAT('ä','+','¥','+','©') (경고 메시지가 발생하지 않도록 형식화된 Latin-1 문자열 리터럴 사용.) |
|
UTF-8 문자열 |
utf8# |
utf8#'ä+漢+🙏' |
' C3 A4 2B E6 BC A2 2B F0 9F 99 8F' |
CONCAT (utf8#'ä','+',utf8#'漢','+',utf8#'🙏') |
혼합 형식 문자열 |
latin1utf8? |
latin1utf8?'ä+漢+🙏' |
' E4 2B E6 BC A2 2B F0 9F 99 8F' |
CONCAT ('ä','+',utf8#'漢','+',utf8#'🙏') |
[입력 데이터 모니터](EDM)에서 모니터링: 초기값 및 16진수, 두 가지 표현이 가능합니다.
프로그래밍 에디터에서 모니터링 본문 및 도구 팁에서 기본 표현, 도구 팁에서만 16진수 표현.
문자열 선언
POU 헤더에서 STRING 형식 변수를 선언하려면 다음 구문을 사용합니다.
STRING[n], 여기서 n은 바이트 수입니다.
기본 초기값은(예: POU 헤더 또는 글로벌 변수 리스트에서 변수 선언의 경우) '', 즉, 빈 문자열입니다.
잘못된 문자열
잘못된 문자열의 기준
문자열 문자에 예약된 최대 바이트 수는 음수이거나 32767보다 큽니다.
문자열 문자에 포함된 현재 바이트 수는 음수이거나 32767보다 큽니다.
문자열 문자를 포함하는 현재 바이트 수가 문자열에 예약된 최대 바이트 수보다 큽니다.
PLC의 문자열 내부 메모리 구조
문자열의 각 문자는 1바이트로 저장됩니다. 문자열의 메모리 영역은 헤더(2워드)와 2문자마다 1워드로 구성됩니다.
첫 워드에는 문자열에 예약된 바이트 수가 포함됩니다.
두 번째 워드에는 문자열의 현재 바이트 수가 포함됩니다.
이후 워드는 각각 2바이트의 문자열 문자가 포함됩니다.
STRING[n]의 특정 메모리 영역을 예약하려면 다음 공식을 사용하여 문자 길이를 지정합니다.
메모리 크기 = 2워드(헤더) + (n+1)/2워드(바이트)
메모리는 워드 단위로 구성됩니다. 따라서 워드 수는 항상 다음 전체 숫자에 반올림됩니다.
워드 오프셋 |
상위 바이트 |
하위 바이트 |
|---|---|---|
0 |
문자열 문자에 예약된 최대 바이트 수 |
|
1 |
문자열 문자에 포함된 현재 바이트 수 |
|
2 |
바이트 2 |
바이트 1 |
3 |
바이트 4 |
바이트 3 |
4 |
바이트 6 |
바이트 5 |
... |
... |
... |
1+(n+1)/2 |
바이트 n |
바이트 n-1 |
문자 인코딩
Latin-1 및 UTF-8 문자 인코딩은 유니코드 블록 C0 제어 및 기본 라틴에 정의된 대로, 0x00~0x7F 범위의 문자를 ASCII 문자와 동일하게 처리합니다.

Latin-1 문자 인코딩은 유니코드 블록 C1 제어 및 Latin-1 Supplement에 정의된 대로 0x80~0xFF 범위의 문자를 처리합니다.

UTF-8 문자 인코딩은 0x80의 유니코드 문자를 다음과 같이 처리합니다.
UTF-8 바이트 시퀀스(이진 표시)
유니코드 범위
0xxxxxxx
0000 0000 – 0000 007F
110xxxxx 10xxxxxx
0000 0080 – 0000 07FF
1110xxxx 10xxxxxx 10xxxxxx
0000 0800 – 0000 FFFF
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
0001 0000 – 0010 FFFF
UTF-8 문자 인코딩 사용 방법
사전 주의사항
펌웨어 명령에 의한 UTF-8 문자 인코딩의 올바른 처리는 보장할 수 없으며, 명시적이고 상세하게 확인해야 합니다!
주석
UTF-8 문자열로 작업할 때는 UTF-8 문자열만 사용하고, UTF-8 문자열과 비 UTF-8 문자열의 혼합을 피하는 것이 좋습니다.
UTF-8 문자열과 비 UTF-8 문자열을 혼합할 때, 비 UTF-8 문자열은 0x00~0x7F 범위의 문자만 포함해야 합니다.
LEN, MID, LEFT; INSERT, DELETE, RIGHT와 같은 펑션은 바이트 지향적입니다. UTF-8 문자열과 함께 사용하면 펑션에서 가정한 바이트 번호 및 위치가 UTF-8 문자열의 문자 번호 및 위치와 일치하지 않을 수 있습니다.
예
입력
utf8#'敬具' (' E6 95 AC E5 85 B7')
동작
LEN(utf8#'敬具')결과
6
바이트 크기 및 UTF-8 문자의 시작 바이트 위치에 해당하지 않는 바이트 번호 및 위치를 가진 UTF-8 문자열에 바이트 지향 문자열 펑션을 적용하면 결과가 유효하지 않은 UTF-8 문자열이 됩니다.
예
입력
utf8#'敬具' (' E6 95 AC E5 85 B7')
동작
MID(IN := utf8#'敬具', L := 3, P := 4)결과
utf8#'具' (' E5 85 B7')
동작
MID(IN := utf8#'敬具', L := 3, P := 3)결과
'Œ$85' (' AC E5 85')
UTF-8 결과 문자열이 타겟 문자열보다 큰 경우, 결과는 유효하지 않은 UTF-8 문자열일 수 있습니다.
예
입력
utf8#'敬具' (' E6 95 AC E5 85 B7')
STRING[5]으로 정의된 sString5
동작
sString5:=utf8#'敬具'결과
sString5: utf8?'敬å$85' (' E6 95 AC E5 85')
유니코드 0x80~0xFF 범위의 특수 문자는 8비트 문자열 또는 UTF-8 문자열로 입력되는지 여부에 따라 다른 결과를 생성합니다.
예
입력
'ö' (' F6')
utf8#'ö' (' C3 B6')
동작
LEN('ö')결과
1
동작
LEN(utf8#'ö')결과
2
동작
'ö'= utf8#'ö'
결과
FALSE
UTF-8 문자열에서 0x80~0xFF 범위의 문자로 8비트 문자열을 검색하면(그 반대도 마찬가지) 예상치 못한 결과가 발생할 수 있습니다.
예
입력
utf8#'敬具' (' E6 95 AC E5 85 B7')
'å' (' E5')
동작
FIND(IN1 := utf8#'敬具', IN2 :='å')결과
4
EN/ENO로 문자열 펑션
사다리 다이어그램(LD) 및 펑션블럭 다이어그램(FBD)
입력 허가(EN) 및 출력 허가(ENO) 접점이 있는 STRING 명령은 LD 및 FBD에서 서로 연결될 수 없습니다. 먼저 EN/ENO가 없는 STRING 명령을 연결한 후 마지막 위치에 EN/ENO가 있는 명령을 추가합니다. 그러면 입력 허가(EN)는 전체 결과의 출력을 제어합니다.
이 배열은 가능하지 않습니다.
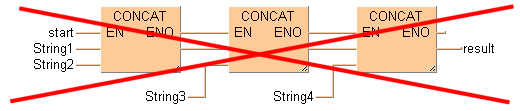
이 배열은 가능합니다.
