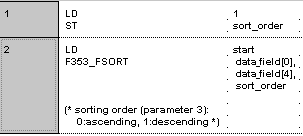
 F353_FSORT
F353_FSORT실수 데이터 테이블에서 데이터 정렬(부동 소수점 데이터 테이블)
이 함수는 데이터 테이블의 값(+/- 부호 포함)을 오름차순 또는 내림차순으로 정렬합니다.
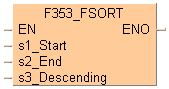
입력
정렬할 데이터 테이블의 시작 영역
정렬할 데이터 테이블의 끝 영역
정렬 순서 지정:
0 = 오름차순
1 = 내림차순
F 명령을 사용하는 대신 해당 FP7 명령을 사용하는 것이 좋습니다.FP_DATA_SORT 데이터 테이블의 데이터 정렬
입력 s1_Start는 데이터 테이블의 시작 영역을 지정하고 s2_End는 끝을 지정합니다. 입력 s3_Descending에서 정렬 순서를 결정합니다.
입력 s3_Descending에서 다음 값을 입력할 수 있습니다.
0 |
오름차순(즉, 가장 작은 값부터 시작) |
1 |
내림차순(즉, 가장 큰 값부터 시작) |
데이터는 입력 s1에서 입력한 값에 따라 지정한 순서의 버블 정렬을 통해 정렬됩니다. 워드 비교 수는 워드 수 제곱에 비례하여 증가하므로, 워드 수가 크면 정렬 프로세스에 시간이 걸릴 수 있습니다. 입력 s1_Start=s2_End 값이 정렬이 수행되지 않습니다.
입력 s1_Start의 변수 어드레스가 s2_End보다 큰 경우
입력 s1_Start와 s2_End의 값 어드레스 영역이 다른 경우
부동 소수점 값이 처리 범위를 초과하는 경우.
입력 s1_Start의 변수 어드레스가 s2_End보다 큰 경우
입력 s1_Start와 s2_End의 값 어드레스 영역이 다른 경우
부동 소수점 값이 처리 범위를 초과하는 경우.

이 펑션 프로그램 시 사용한 모든 입력과 출력 변수는 POU 헤더에서 선언되었습니다. 모든 프로그래밍 언어에 같은 POU 헤더를 사용합니다.

VAR
CalculateY: BOOL:=FALSE;
xValue: REAL:=4.0;
yValue: REAL:=0.0;
xyValues: XY_DUT;
END_VAR
VAR
CalculateY: BOOL:=FALSE;
xValue: REAL:=4.0;
yValue: REAL:=0.0;
xyValues: XY_DUT;
END_VAR이 예에서는 입력 변수 sort_order가 선언됩니다. 하지만 본문에서 함수의 입력 접점에 직접 정수(예: 내림차순의 경우 1)를 쓸 수 있습니다.
변수 start가 TRUE로 설정되면 펑션이 실행됩니다.
배열 data_field의 요소가 내림차순으로 정렬됩니다.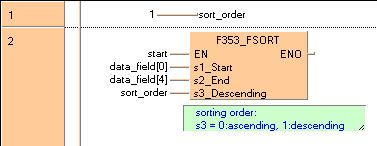
BODY
WORKSPACE
NETWORK_LIST_TYPE := NWTYPELD ;
ACTIVE_NETWORK := 0 ;
END_WORKSPACE
NET_WORK
NETWORK_TYPE := NWTYPELD ;
NETWORK_LABEL := ;
NETWORK_TITLE := ;
NETWORK_HEIGHT := 3 ;
NETWORK_BODY
B(B_VAROUT,,sort_order,9,0,11,2,);
B(B_VARIN,,1,7,0,9,2,);
L(1,0,1,3);
END_NETWORK_BODY
END_NET_WORK
NET_WORK
NETWORK_TYPE := NWTYPELD ;
NETWORK_LABEL := ;
NETWORK_TITLE := ;
NETWORK_HEIGHT := 9 ;
NETWORK_BODY
B(B_VARIN,,output,8,1,10,3,);
B(B_F,F353_FSORT,,10,0,19,6,,?DEN?D@'s1'?Ds2?Ds3?AENO);
B(B_VARIN,,sort_order,8,4,10,6,);
B(B_VARIN,,data field[0],8,2,10,4,);
B(B_VARIN,,data field[4],8,3,10,5,);
B(B_COMMENT,,sorting order:ø^s3 = 0:ascending~ 1:descending,11,6,26,8,);
L(1,0,1,9);
END_NETWORK_BODY
END_NET_WORK
END_BODYsort_order:=1;
IF start then
F353_FSORT( s1_Start:= data_field[0],
s2_End:= data_field[4],
s3_Descending:= sort_order);
END_IF;