STRING
数据类型STRING由两部分组成:
一个包含最大和当前字节数的标头
一个序列(字符串),最多32767字节,具体取决于PLC的存储器大小,可以包含任何类型的字符编码,甚至二进制数据
有关详细信息,请参见“PLC上的字符串内部存储器结构”。
使用数据类型为STRING的变量的操作实例:
通过字符串文字或转换功能来填充字符串变量,比如WORD_TO_STRING、FP_FORMAT_STRING...
通过字符串指令来使用和操作字符串变量,比如CONCAT、LEFT...
通过特殊的地址功能(比如Adr_OfVarOffs...)或通过特殊的重叠DUT(比如预定义的重叠DUT STRING32_OVERLAPPING_DUT)任意访问字符串变量
通过文件、HTML页面或监控命令与外部设备交换数据
在Control FPWIN Pro7中,以下两种字符编码受字符串文字和监控特别支持:
Latin-1编码,这是一种符合ISO 8859-1 (Latin-1)的固定单位字符编码,允许0x00–0xFF的Unicode字符
UTF-8编码,这是一种多字节字符编码,字符由1到4个字节组成,允许0x00–0x10FFFF的所有Unicode字符。
Latin-1和UTF-8字符编码将0x00–0x7F范围内的字符完全视为ASCII字符。
应该防止混用字符编码,有关详细信息,请参见“如何使用UTF-8字符编码”
字符串文字
字符串文字包含单引号字符(')内的转义序列的字符序列。
字符串文字可以用于:
在声明编辑器中初始化数据类型为STRING的变量
在编程本体中作为输入参数
以下是可用的字符串文字:
Latin-1编码的字符串文字,允许0x00–0xFF的Unicode字符
没有任何前缀的未分类Latin-1编码字符串文字,比如'abc'。当它们包含0x80–0xFF范围内的非ASCII字符时,比如'äöü',会生成一个警告。
未分类的Latin-1字符串文字的示例:
Unicode块
未分类的Latin-1字符串文字
十六进制表示的字节
备注
空字符串
''
''
基本拉丁字母(0x00–0x7F)
'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
'0-9'
' 30 2D 39'
'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
拉丁字母-1补充(0x80–0xFF)
'¥£©®'
' A5 A3 A9 AE'
这种用法会生成警告消息。
'歨'
' B5 A1 BF'
'äöüß'
' E4 F6 FC DF'
'ÄÖÜ'
' C4 D6 DC'
带有前缀latin1#的已分类Latin-1编码字符串文字,比如latin1#'abc'或latin1#'äöü'
已分类的Latin-1字符串文字的示例:
Unicode块
已分类的Latin-1字符串文字
十六进制表示的字节
备注
空字符串
latin1#''
''
基本拉丁字母(0x00–0x7F)
latin1#'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
latin1#'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
latin1#'0-9'
' 30 2D 39'
latin1#'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
拉丁字母-1补充(0x80–0xFF)
latin1#'¥£©®'
' A5 A3 A9 AE'
这种用法不会生成警告消息。
latin1#'歨'
' B5 A1 BF'
latin1#'äöüß'
' E4 F6 FC DF'
latin1#'ÄÖÜ'
' C4 D6 DC'
UTF-8字符串文字
带有前缀utf8#的UTF-8编码字符串文字(比如utf8#'abc'、utf8#'äöü'或utf8#'ä+漢+🙏')能够编码1到4个字节内、0x00–0x10FFFF的所有Unicode字符。
UTF-8字符串文字的示例
每个字符的字节
Unicode块
UTF-8字符串文字
十六进制表示的字节
空字符串
utf8#''
''
1
基本拉丁字母
utf8#'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
utf8#'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
utf8#'0-9'
' 30 2D 39'
utf8#'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
2
拉丁字母-1补充
utf8#'¥£©®'
' C2 A5 C2 A3 C2 A9 C2 AE'
utf8#'歨'
' C2 B5 C2 A1 C2 BF'
utf8#'äöüß'
' C3 A4 C3 B6 C3 BC C3 9F'
utf8#'ÄÖÜ'
' C3 84 C3 96 C3 9C'
希腊语
utf8#'αβγ'
' CE B1 CE B2 CE B3'
3
CJK平假名
utf8#'ゖ'
' E3 82 96'
CJK片假名
utf8#'ヺ'
' E3 83 BA'
CJK统一
utf8#'囆'
' E5 9B 86'
4
CJK统一
utf8#'𫜴'
' F0 AB 9C B4'
表情符号
utf8#'🙏'
' F0 9F 99 8F'
转义字符序列
转义字符序列可用于8位字符串文字和UTF-8字符串文字中。
美元符号($)加上两个十六进制数的三个字符组合被译为八位字符代码的十六进制表示法。
字符串文字
十六进制表示的字节
备注
'$02$03'
utf8#'$02$03'
' 02 03'
STX, ETX
'$E5$9B$86'
utf8#'$E5$9B$86'
' E5 9B 86'
utf8#'囆'
'$F0$9F$99$8F'
utf8#'$F0$9F$99$8F'
' F0 9F 99 8F'
utf8#'🙏'
注释如果在UTF-8字符串中输入无效的UTF-8字节序列,则结果将是无效的UTF-8字符串。
示例
输入
utf8#'敬 敬$FE$FF敬 具' (' E6 95 AC FE FF E5 85 B7')
sString10定义为STRING[10]
操作
sString10:= utf8#'敬敬$FE$FF敬具'结果
sString10: utf8?'敬敬þÿ敬具' (' E6 95 AC FE FF E5 85 B7')
以美元符号开头的两个字符组合以表中所示编译:
字符串文字
十六进制表示的字节
备注
'$$'
utf8#'$$'
' 24'
美元符号
'$''
utf8#'$''
' 27'
单引号
'$L'或'$l'
utf8#'$L'或utf8#'$l'
' 0A'
换行符
'$N'或'$n'
utf8#'$N'或utf8#'$n'
' 0D 0A'
新行符
'$P'或'$p'
utf8#'$P'或utf8#'$p'
' 0C'
换页符(页)
'$R'或'$r'
utf8#'$R'或utf8#'$r'
' 0D'
回车符
'$T'或'$t'
utf8#'$T'或utf8#'$t'
' 09'
制表Tab
监控取决于字符串类型
在监控过程中,选择默认表示,以查看根据检测到的字符编码正确显示的字符串字节:
字符串类型 |
前缀 |
默认表示 |
十六进制表示 |
编程示例ST编辑器 |
|---|---|---|---|---|
Latin-1编码字符串 |
- |
'a+b+c' |
' 61 2B 62 2B 63' |
CONCAT('a','+','b','+','c') |
latin1# |
latin1#'ä+¥+©' |
' E4 2B A5 2B A9' |
CONCAT('ä','+','¥','+','©') (使用已分类Latin-1字符串文字,以避免出现警告消息) |
|
UTF-8字符串 |
utf8# |
utf8#'ä+漢+🙏' |
' C3 A4 2B E6 BC A2 2B F0 9F 99 8F' |
CONCAT (utf8#'ä','+',utf8#'漢','+',utf8#'🙏') |
混合类型字符串 |
latin1utf8? |
latin1utf8?'ä+漢+🙏' |
' E4 2B E6 BC A2 2B F0 9F 99 8F' |
CONCAT ('ä','+',utf8#'漢','+',utf8#'🙏') |
在[执行数据监控(Y)](EDM)中监控:有两种表示:默认和十六进制。
在编程编辑器中监控:本体和提示工具中的默认表示,仅在提示工具中的十六进制表示。
字符串声明
若要在POU头中声明STRING类型变量,请使用以下语法:
STRING[n],其中n = 字节数
默认初始值,例如POU头或全局变量列表中的变量声明为'',即空字符串。
无效字符串
无效字符串的标准:
为字符串字符保留的最大字节数为负或大于32767
字符串字符中包含的当前字节数为负或大于32767
包含字符串字符的当前字节数大于为字符串保留的最大字节数
PLC上字符串的内部存储器结构
字符串的每个字符均以一个字节存储。字符串的内存区包含头(两个字),每两个字符为一个字。
第一个字包含为字符串保留的字节数。
第二个字包含字符串中的当前字节数。
随后的每个字包含字符串字符的两个字节。
若要为STRING[n]保留某个内存区,请使用以下公式指定字符串长度:
存储容量 = 2字(头) + (n+1)/2字(字节)
以字单元组织存储器。因此,字数始终向上舍入下一个整数。
字偏移 |
高字节 |
低字节 |
|---|---|---|
0 |
为字符串字符保留的最大字节数 |
|
1 |
字符串字符中包含的当前字节数 |
|
2 |
字节2 |
字节1 |
3 |
字节4 |
字节3 |
4 |
字节6 |
字节5 |
... |
... |
... |
1+(n+1)/2 |
字节n |
字节n-1 |
字符编码
Latin-1和UTF-8字符编码将0x00–0x7F范围内的字符完全视为Unicode块C0控制和基本Latin中定义的ASCII字符。
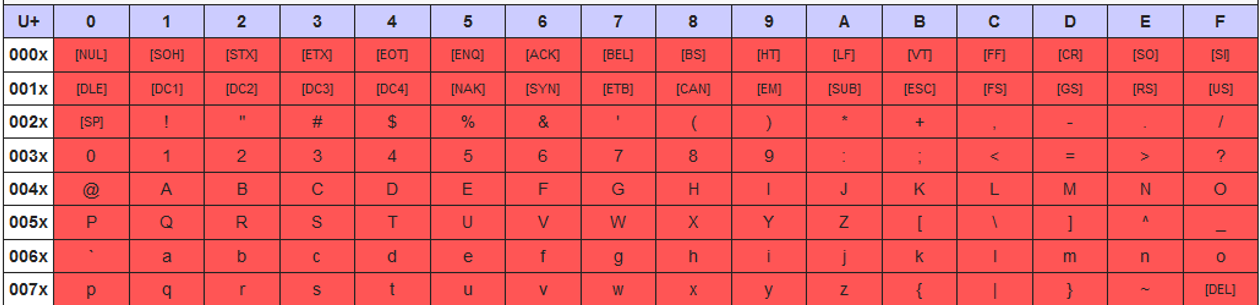
Latin-1字符编码按照Unicode块C1控制和Latin-1补充中的定义来处理0x80–0xFF范围内的字符。
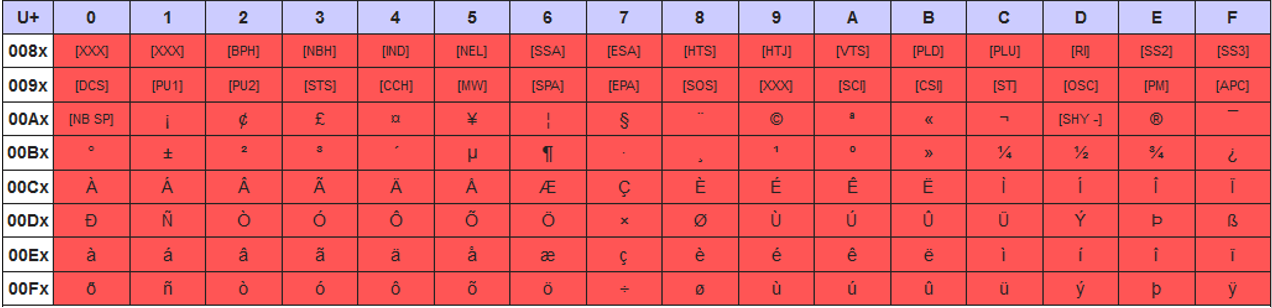
UTF-8字符编码将0x80以上的Unicode字符视为:
UTF-8字节序列(二进制表示)
Unicode范围
0xxxxxxx
0000 0000 – 0000 007F
110xxxxx 10xxxxxx
0000 0080 – 0000 07FF
1110xxxx 10xxxxxx 10xxxxxx
0000 0800 – 0000 FFFF
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
0001 0000 – 0010 FFFF
如何使用UTF-8字符编码
注意事项
由于不能保证固件指令正确处理UTF-8字符编码,因此必须对其进行明确且详细的检查!
标注
使用UTF-8字符串时,强烈建议仅使用UTF-8字符串,并避免将UTF-8字符串和非UTF-8字符串混用!
当混合UTF-8字符串和非UTF-8字符串时,非UTF-8字符串应仅包含0x00–0x7F范围内的字符。
LEN、MID、 LEFT、INSERT、DELETE、RIGHT等功能是面向字节的。当它们与UTF-8字符串一起使用时,该函数假定的字节数和位置可能与UTF-8字符串的字符数和位置不对应。
示例
输入
utf8#'敬具' (' E6 95 AC E5 85 B7')
操作
LEN(utf8#'敬具')结果
6
当对字节数和位置与UTF-8字符的字节大小和起始字节位置不对应的UTF-8字符串应用面向字节的字符串函数时,结果将是无效的UTF-8字符串。
示例
输入
utf8#'敬具' (' E6 95 AC E5 85 B7')
操作
MID(IN := utf8#'敬具', L := 3, P := 4)结果
utf8#'具' (' E5 85 B7')
操作
MID(IN := utf8#'敬具', L := 3, P := 3)结果
'Œ$85' (' AC E5 85')
如果UTF-8结果字符串大于目标字符串,则结果可能是无效的UTF-8字符串。
示例
输入
utf8#'敬具' (' E6 95 AC E5 85 B7')
sString5定义为STRING[5]
操作
sString5:=utf8#'敬具'结果
sString5: utf8?'敬å$85' (' E6 95 AC E5 85')
Unicode范围0x80–0xFF的特殊字符会产生不同的结果,具体取决于是以8位字符字符串输入还是以UTF-8字符串输入。
示例
输入
'ö' (' F6')
utf8#'ö' (' C3 B6')
操作
LEN('ö')结果
1
操作
LEN(utf8#'ö')结果
2
操作
'ö'= utf8#'ö'
结果
FALSE
在UTF-8字符串中搜索字符范围0x80–0xFF的8位字符串,反之亦然,可能会导致意外结果。
示例
输入
utf8#'敬具' (' E6 95 AC E5 85 B7')
'å' (' E5')
操作
FIND(IN1 := utf8#'敬具', IN2 :='å')结果
4
带有EN/ENO的STRING函数
梯形图(LD)和功能块图(FBD)
带有输入有效(EN)和输出有效(ENO)触点的字符串指令可能无法在LD和FBD中互相连接。首先连接不带EN/ENO的字符串指令,然后将带有EN/ENO的指令添加到最后位置。然后输入有效(EN)控制总体结果的输出。
无法进行此排列:
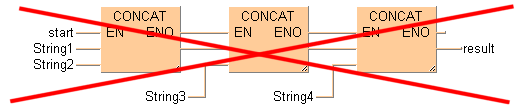
可以进行此排列:
