


 MID
MID中間位置からの文字列抽出
MID命令は、INで指定される文字列を、開始位置Pから、L文字分を抽出します。Pは、1の場合、文字列の1文字目を表します。演算結果の文字列は、出力変数に書き込まれます。
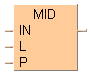
入力
先頭の入力文字列
コピーする入力文字列の文字数
コピーする入力文字列の開始位置。1は文字列の1文字目になります
出力
コピー文字列
この命令をUTF-8文字列で使用する場合は、データ型STRINGのUTF-8文字列についての注意事項をご参照ください。
開始位置と抽出する文字数の合計が、入力文字列の文字数を超えないようにしてください。例えば、10文字の文字列から5文字を抽出するとき、先頭位置に7を指定すると最後の4文字しか転送されません。
出力文字列が「データ型」フィールドで宣言された出力変数の文字列長よりも長い場合、出力変数が保持できる数と同じ文字数が、演算結果に転送されます。システム変数sys_bIsCarryがセットされます。
入力または出力に適用される文字列が無効な文字列のとき
入力または出力に適用される文字列が無効な文字列のとき
"データ型"フィールドで宣言された出力変数の文字列長よりも、出力文字列が長いときON

POUヘッダには、このプログラムで使用するすべての入力変数と出力変数を宣言します。 POUヘッダは全プログラム言語で使用できます。

VAR
sInputString: STRING[32]:='A better life. A better world.';
(*sample string*)
iNumberOfCharacters: INT:=15;
(*characters to be delivered*)
iStartPos: INT:=16;
(*position to start copying*)
sResultString: STRING[15]:='';
(*result here: 'A better world.'*)
END_VARこの例では、入力変数(sInputString、iNumberOfCharacters、iStartPos)が宣言されています。ファンクションの入力ピンに、文字列、転送する文字数、開始位置を直接入力することもできます。POUヘッダ、ボディとも、文字列には引用符をつけてください。
入力変数sInputStringのiStartPos (16)からiNumberOfCharacters (15)文字分がsResultStringに格納されます。

BODY
WORKSPACE
NETWORK_LIST_TYPE := NWTYPELD ;
ACTIVE_NETWORK := 0 ;
END_WORKSPACE
NET_WORK
NETWORK_TYPE := NWTYPELD ;
NETWORK_LABEL := ;
NETWORK_TITLE := ;
NETWORK_HEIGHT := 5 ;
NETWORK_BODY
B(B_F,MID!,,22,0,27,5,,?DIN?DL?DP?C);
B(B_VARIN,,sInputString,20,1,22,3,);
B(B_VARIN,,iNumberOfCharacters,20,2,22,4,);
B(B_VARIN,,iStartPos,20,3,22,5,);
B(B_VAROUT,,sResultString,27,1,29,3,);
L(1,0,1,5);
END_NETWORK_BODY
END_NET_WORK
END_BODYsResultString:=MID(IN:=sInputString, L:=iNumberOfCharacters, P:=iStartPos);